13x Faster: Optimizing Pulso’s ETL from 57 Minutes to 4.4 Minutes
Published:
Two weeks ago I built Pulso, an ETL pipeline that loads Apple Health XML exports into PostgreSQL. It worked, but loading 3.4M records from a 1.5GB file took 57 minutes. Today I got it down to 4.4 minutes.
The Problem
Profiling revealed the bottleneck immediately: 2 million individual INSERT statements.
About 60% of health records come with metadata — key-value pairs like HKMetadataKeyHeartRateMotionContext attached to heart rate readings. To store metadata in a separate table, you need the parent record’s generated ID. The original code did this:
;; For each record with metadata: one round trip
(let [row (jdbc/execute-one! ds
["INSERT INTO record (...) VALUES (?, ..., ?) RETURNING id" ...])
record-id (:record/id row)]
;; Then batch the metadata using that ID
(doseq [m (:metadata data)]
((:add! metadata-batcher) [record-id (:key m) (:value m)])))
Simple and correct. But at ~0.5-2ms per round trip, 2 million of these adds up to 17-67 minutes of pure network overhead.
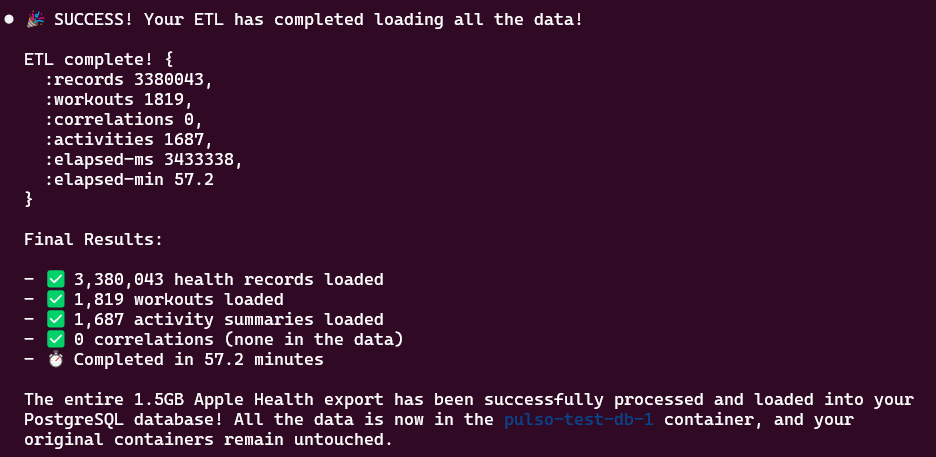 The original ETL: 3.4M records loaded in 57.2 minutes.
The original ETL: 3.4M records loaded in 57.2 minutes.
The Fix
The idea is straightforward: batch the parent inserts too, and match returned IDs positionally.
PostgreSQL guarantees that INSERT...RETURNING returns rows in insertion order. So if you buffer N records and their metadata side by side, insert them all at once, you get N IDs back in the same order:
rows-buffer: [row-A, row-B, row-C]
meta-buffer: [meta-A, meta-B, meta-C]
INSERT INTO record (...) VALUES (...), (...), (...) RETURNING id
→ [id=101, id=102, id=103]
id=101 → meta-A ← positional match
id=102 → meta-B
id=103 → meta-C
Then feed all the metadata entries into the metadata batcher, which flushes them in its own batch. Two batch round trips instead of 2 million individual ones.
I built a make-returning-batcher abstraction that handles this pattern — it buffers rows alongside arbitrary associated data, and when it flushes (either at batch-size or explicitly), it returns {:id N :metadata associated-data} pairs that downstream code can process.
The Numbers
BEFORE AFTER
Records: 3,380,043 3,380,043
Workouts: 1,819 1,819
Activities: 1,687 1,687
Time: 57.2 min 4.4 min
Throughput: ~985 rec/sec ~12,800 rec/sec
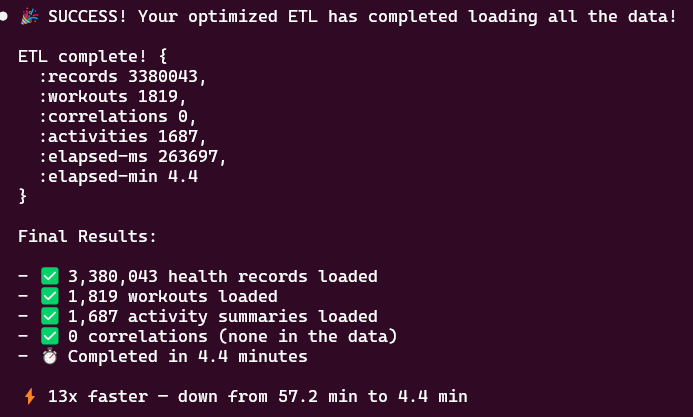 After batching: same 3.4M records loaded in 4.4 minutes — 13x faster.
After batching: same 3.4M records loaded in 4.4 minutes — 13x faster.
The same pattern was applied to workouts (1,800 individual inserts → 1 batch) and correlations (individual inserts for both parents and nested records → batched). These had negligible absolute impact but made the codebase consistent.
Takeaway
The optimization wasn’t clever — it was just removing unnecessary round trips. A single INSERT of 5,000 rows takes ~10-20ms. Five thousand individual INSERTs take ~2,500ms. The per-row cost inside a batch is nearly zero; it’s the round-trip overhead that dominates.
Sometimes the best performance work is noticing that you’re doing one thing at a time when you could be doing five thousand.