Pulso: Building a Production-Grade ETL Pipeline in an Afternoon with Claude Code
Published:
I just shipped Pulso, a complete Apple Health XML to PostgreSQL ETL pipeline that processes 1.5GB+ health exports and loads 3.4M+ health records into a normalized relational model. What’s remarkable? The entire project—from concept to production—was built in a single afternoon using Claude Code with human supervision.
The Challenge
Apple Health exports generate massive XML files containing years of personal health data: activity records, workouts, correlations, summaries. But the XML format is deeply nested and not conducive to analysis. The goal: stream the XML, normalize it, and load it into PostgreSQL with zero memory overhead.
The Architecture
Pulso uses a single-pass streaming approach that keeps memory constant at -Xmx512m regardless of file size:
XML File (1.5GB+)
↓
StAX Streaming Parser (lazy)
↓
Iterate root children (no head retention)
↓
┌──────┬────────┬──────────┬──────────────┬──────────────┐
Me Record Workout Correlation ActivitySummary
│ │ │ │ │
transform transform transform transform transform
│ │ │ │ │
INSERT BATCH INSERT+ INSERT+ BATCH
(1) (5000) children children (1000)
Key design decisions:
- Streaming XML via
clojure.data.xml(StAX) — children are lazy, so only one element is in memory at a time - Lookup caching — source, device, record type, and unit tables are cached in atoms (~50-100 unique values)
- Batch inserts — records accumulate in buffers and flush via
INSERT ON CONFLICTevery 5,000 rows - Idempotent loads — all tables are truncated before each run
The Data Model
The schema normalizes into 16 tables across lookup, dimension, and fact categories:
- Lookup tables:
source,device,record_type,unit - User profile:
user_profile - Records:
record,record_metadata(3.4M+ rows) - Workouts:
workout,workout_metadata,workout_event,workout_statistics,workout_route(1,800+ workouts) - Correlations:
correlation,correlation_metadata,correlation_record - Activity:
activity_summary
From Raw Data to Insights
Once your data is in PostgreSQL, Pulso comes with Metabase — an open-source BI tool for interactive analysis without writing SQL.
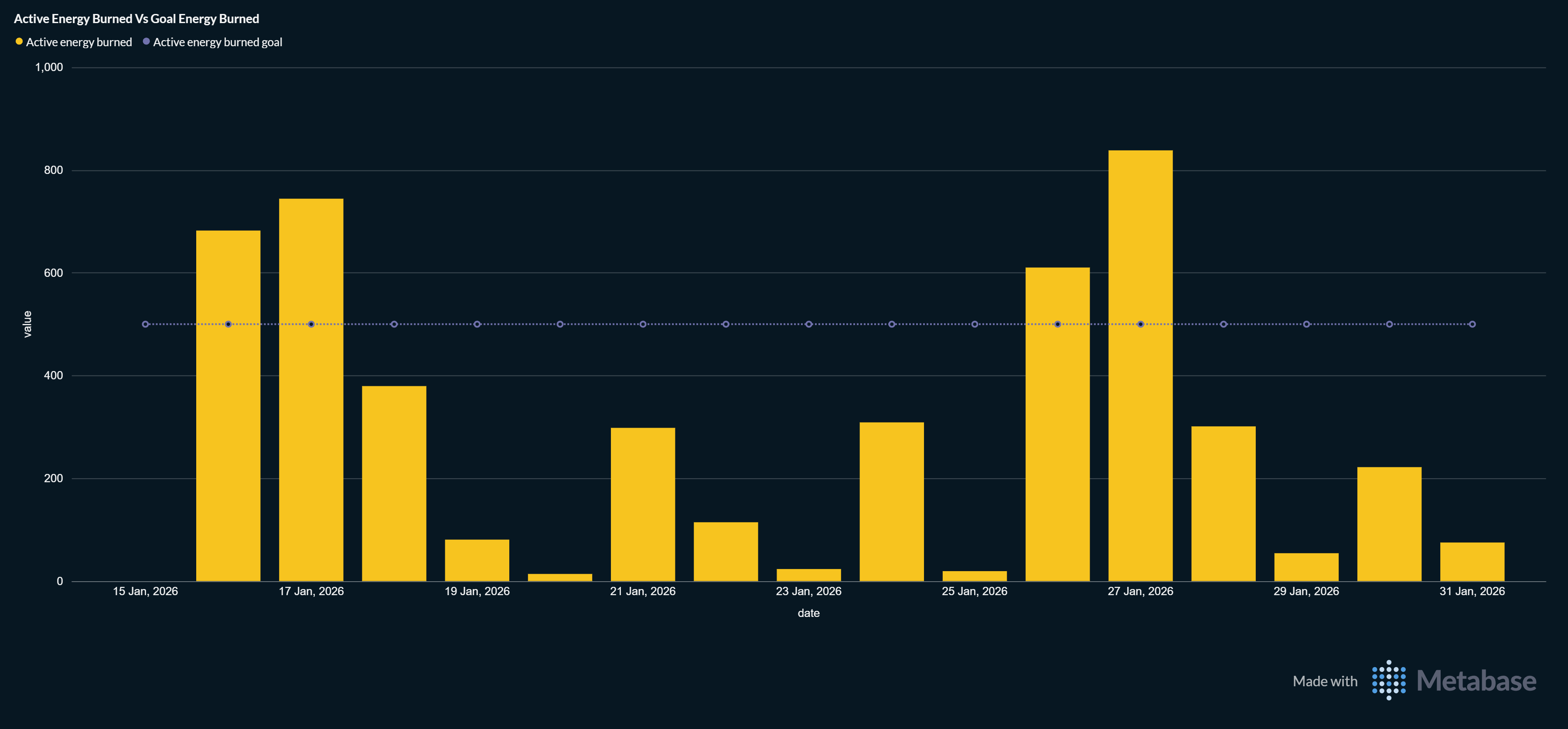
Active Energy Burned vs Goal Energy Burned
Track how your actual calorie burn compares to your daily goals over time. Perfect for fitness trending.
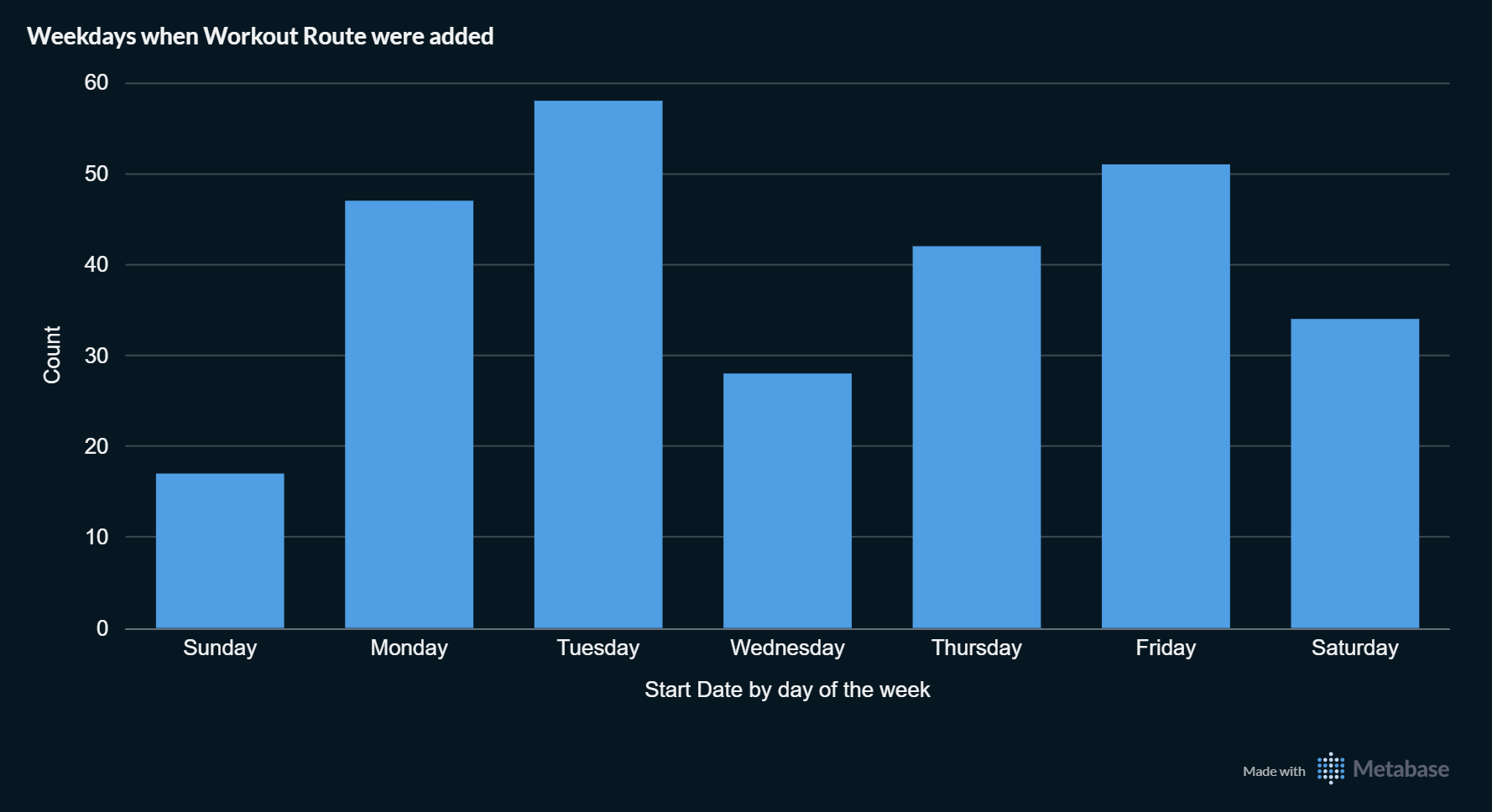
Workout Route Patterns
Discover when you’re most active. This dashboard shows which days of the week you add workout routes, revealing patterns in your exercise habits.
All Metabase dashboards are interactive, filterable, and shareable. Run docker compose up and you get a fully functional analytics stack at http://localhost:3000.
Production-Ready Out of the Box
What made this feasible in an afternoon was not cutting corners, but leveraging the right tools:
Testing: 37 integration tests covering batch processing, lookup caching, parent-child ID propagation, and end-to-end pipeline correctness. All passing.
Deployment: Docker Compose brings up PostgreSQL + Pulso. Multi-stage Dockerfile keeps the uberjar minimal.
CI/CD: GitHub Actions automatically runs syntax checks, all 37 tests, builds the uberjar, and uploads artifacts on every push.
Documentation: Comprehensive README with architecture diagrams, test organization, and usage examples.
The Role of Claude Code
Claude Code handled the heavy lifting:
- Generated all 9 test files with complex setup/teardown logic
- Wrote the core ETL orchestration and data transformation modules
- Built comprehensive documentation
- Set up GitHub Actions workflows
- Debugged and fixed issues iteratively
My role was primarily supervision and direction: validating architectural decisions, reviewing test patterns, making course corrections when assumptions proved wrong.
This collaboration model—AI for implementation, human for judgment—proved remarkably efficient.
Performance
On a modern laptop with -Xmx512m:
- 1.5GB XML file → 3.4M records → completes in seconds
- Zero memory spikes due to streaming architecture
- Connection pooling via HikariCP
- Batch insert throughput: 5,000 records/batch
Open Source
Pulso is available on GitHub under the MIT license. It’s a complete reference implementation for:
- Streaming XML processing in Clojure
- Idempotent ETL pipelines
- Production-grade test infrastructure
- CI/CD automation with GitHub Actions
If you have Apple Health data you want to explore, Pulso + Metabase gives you a fully visualizable analytics stack.
Reflection: This project proves that “afternoon projects” aren’t a meme in the age of AI-assisted development. But they still require human judgment about architecture, testing strategy, and deployment. The multiplier effect of AI handling boilerplate while humans focus on decisions is real.